<sup id="gowow"></sup>
<menu id="gowow"></menu>
<dfn id="gowow"></dfn>
如若轉載,請注明出處:http://www.diyseal.cn/product/42.html
更新時間:2026-04-24 02:41:31
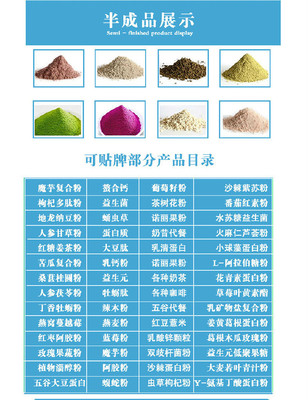
即食代餐粉沖調飲品固體飲料粥料五谷雜糧打粉配方OEM貼牌代加工
足貼來料加工 足貼 庭七日用品源頭工廠
代餐粉oem香草味固體飲料加工菊粉oem貼牌代工膳食纖維粉定制
谷菜精營養代餐粉 兒童果蔬代餐粉OEM貼牌 湖北代餐粉加工恒佳生物
【低溫烘焙代餐粉 粗糧紅豆 貼牌代加工 沖調飲品 養生粉圖片】低溫烘焙代餐粉 粗糧紅豆 貼牌代加工 沖調飲品 養生粉
代餐粉
奶昔代餐貼牌
代餐粉代加工廠
蛋 貼牌加工 湖北小林古方生物公司 圖
高清圖片
地址:福建省漳州市龍海區程溪鎮內云村下尾301-1號
Copyright © 2026 www.diyseal.cn 代餐粉加工 喜陽陽福建食品有限公司 代餐粉加工 版權所有 Sitemap
<dfn id="esceo"></dfn>